Is There a Backend-as-a-Service for AI Coding Agents?
TL;DR: Yes. A handful of backends now target AI coding agents directly. InsForge, Base44, Butterbase, and MoonDB are among them. What sets them apart from Supabase or Firebase is that an agent can provision the whole thing from code: a JSON schema in, a hosted database with auth and a REST API out, no dashboard click-through. With MoonDB that's three calls.
What "designed for AI coding agents" actually means
Most backends were built for a person. You sign in, click to create tables, wire up auth in a settings panel, copy keys out of a dashboard, and paste them into your app. An agent like Cursor or Claude Code can't click. Drop one into that flow and it stalls at the first screen that needs a human.
An agent-native backend removes the human step. The whole setup runs over HTTP or through an MCP server, so the agent does the work end to end. Three things make that possible, and they're the test for whether a backend really fits an agent:
It provisions from code. Creating a project, applying a schema, and reading the resulting keys all happen through API calls that return JSON. Nothing waits on a console.
It's declarative. The agent writes what the data looks like: tables, fields, relationships, and who can read and write each one. The service figures out the SQL and runs the migration. No hand-written DDL, no guessing at migration order.
Its errors are instructions. When a schema is wrong, the response says what to fix, not just that something broke. An agent reads that and corrects itself on the next call instead of looping.
Supabase and Firebase can be scripted, and people do script them. But the happy path still runs through a dashboard, the client libraries assume a build step, and the error messages are written for a developer reading a stack trace. In the newer tools, the agent is the primary user and the human reviews the result.
The backends built for this, as of 2026
The category is small, and it already has a name: "agent-native" backends. A few worth knowing:
InsForge is an open-source backend that bundles a stack of services behind a semantic layer an agent can read and provision: Postgres with auto-generated APIs, auth, S3-compatible storage, edge functions, compute and hosting, and an AI model gateway. The source is on GitHub under Apache-2.0.
Base44 leans on its CLI, which it tunes for Claude Code and Cursor so an agent can scaffold backend logic, data models, and APIs from a prompt.
Butterbase is another open-source option: Postgres, auth, storage, functions, an AI gateway, and an MCP server.
Xano comes at it from the no-code side. It's a visual backend builder that's added AI features for generating APIs and logic.
MoonDB sits at the minimal end of that list, and on purpose. It does one thing: turn a JSON schema into a hosted database with a REST API, auth, and file storage, all reachable over plain HTTP or MCP. There's no vector store, no edge-function runtime, no AI gateway. If your generated app needs RAG or a serverless compute layer, InsForge or Butterbase carry more out of the box. If it needs a database with auth and a clean API that an agent can stand up in seconds and a person can actually understand, the smaller surface is the point.
The honest framing: on a feature checklist, Supabase wins. The question that sorts this category is which backend an agent can drive to "done" without a human unblocking it, and how little is left to misunderstand once it's running.
Provision a MoonDB backend the way an agent would
Here's the full path an agent follows to back a generated app, with a to-do app as the canonical first build. Three calls, no dashboard.
Step 1: create a project
One call returns the keys the rest of the flow needs.
curl -X POST https://moondb.ai/v1/projects \
-H "X-API-Key: mk_your_account_key" \
-H "Content-Type: application/json" \
-d '{ "name": "todo-app" }'
{ "data": { "id": "p_7k2d", "admin_key": "sk_...", "public_key": "pk_..." } }The agent keeps the admin_key server-side and uses the public_key for anything that runs in a browser. No human copies anything out of a console.
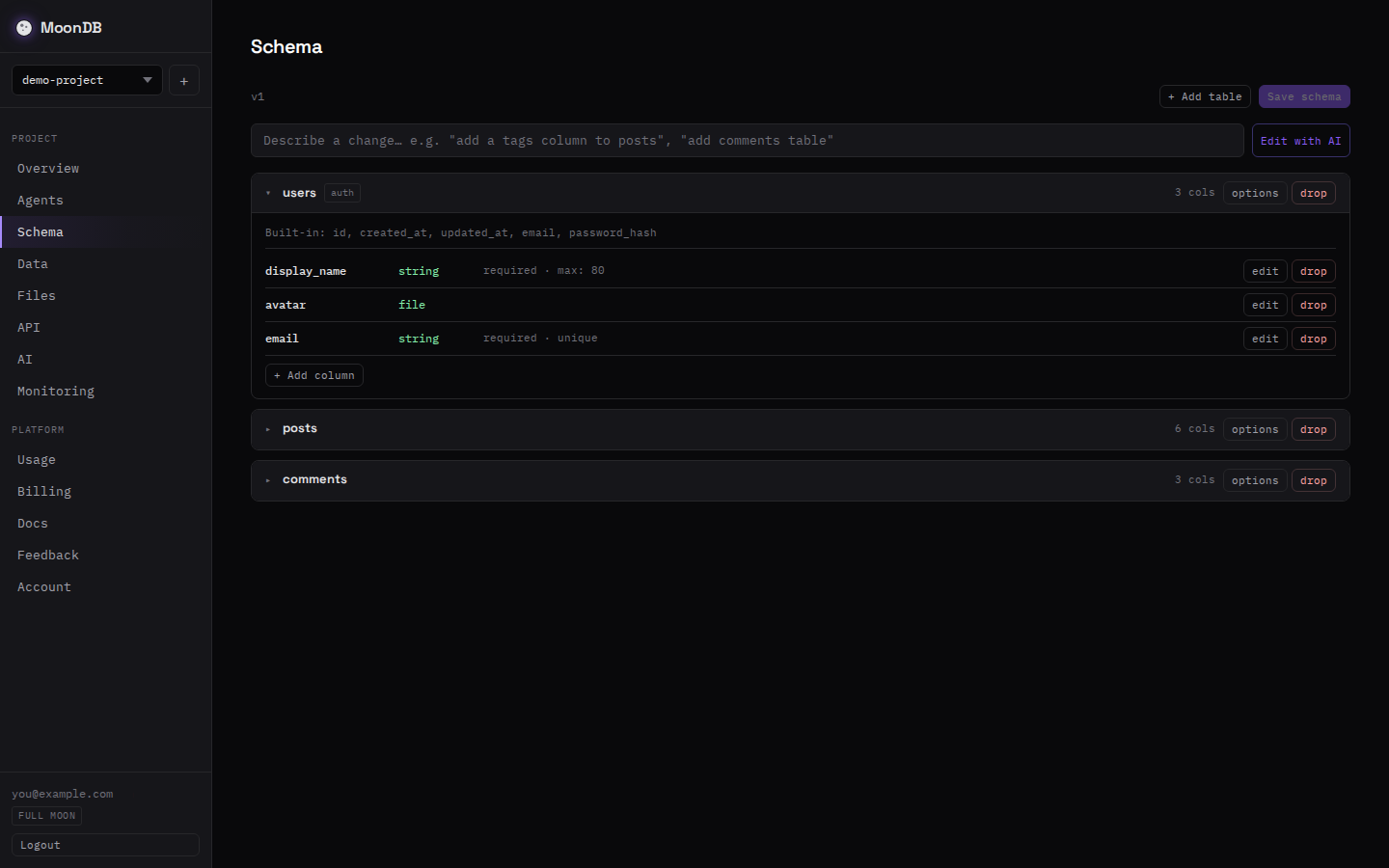
Step 2: send the schema
The agent describes the data as one JSON document and applies it with a single PUT. A to-do app needs users and per-user todos, where each person only sees their own list.
curl -X PUT https://moondb.ai/p/p_7k2d/v1/schema \
-H "X-Admin-Key: sk_..." \
-H "Content-Type: application/json" \
-d @schema.json
{
"tables": {
"users": {
"auth_table": true,
"columns": { "display_name": "string" }
},
"todos": {
"columns": {
"title": "string required max_length 200",
"done": "bool default false",
"due_date": "date",
"priority": { "type": "enum", "values": ["low", "medium", "high"], "default": "medium" },
"user_id": "ref users required"
},
"owner_field": "user_id",
"access": { "read": "owner", "create": "authenticated", "update": "owner", "delete": "owner" }
}
}
}
That document carries the whole security model. "auth_table": true makes users the login table, so MoonDB adds a hidden, required password_hash column and serves signup and login endpoints. The agent never declares the password field. "ref users required" ties each todo to a user. The owner_field with "read": "owner" scopes every read to the logged-in user, so one person's todos never leak into another's response, and the agent didn't write a line of authorization code to get that. create: authenticated lets any signed-in user add a todo. MoonDB also adds id, created_at, and updated_at to every table on its own.
MoonDB reads that, creates the tables, and serves the API immediately. Change the schema later and the agent sends new JSON; MoonDB diffs the two versions and migrates, and it refuses to run a destructive change unless the request opts in. That guardrail keeps an over-eager agent from dropping a column full of data.
Step 3: use the generated API
The endpoints exist the moment the schema applies. The agent signs up an end user, gets a token back, and writes a todo as that user.
# Create an end user
curl -X POST https://moondb.ai/p/p_7k2d/auth/signup \
-H "Content-Type: application/json" \
-d '{ "email": "sam@example.com", "password": "s3cret-pass", "display_name": "Sam" }'
# → { "data": { "user": {...}, "token": "<jwt>", "refresh_token": "...", "expires_in": 3600 } }
# Add a todo as that user
curl -X POST https://moondb.ai/p/p_7k2d/api/todos \
-H "Authorization: Bearer <jwt>" \
-H "Content-Type: application/json" \
-d '{ "title": "Ship the MVP", "priority": "high" }'
The todo lands with user_id set to Sam from the token, because the owner_field rule stamps ownership at write time. When Sam reads GET /p/p_7k2d/api/todos, the read: owner rule scopes the result to Sam's rows. The agent gets working auth and per-user data isolation out of the schema, not out of a pile of middleware it had to write and test.
That's the loop a coding agent can run unattended: create, describe, write. For an agent that speaks Model Context Protocol, MoonDB exposes the same provisioning as MCP tools, so the steps above become tool calls inside the agent's session instead of shell commands.
How the agent-native backends compare
| Supabase / Firebase | InsForge / Butterbase | MoonDB | |
|---|---|---|---|
| Built for | A developer at a dashboard | AI coding agents | AI coding agents |
| How an agent provisions it | Scripted around a dashboard flow | CLI + MCP | Three HTTP calls or MCP |
| Schema source | SQL, dashboard, or migrations | Declarative + AI generation | One JSON document |
| Database | Postgres | Postgres | SQLite on Cloudflare D1 |
| Extra services | Many | Vector DB, edge functions, AI gateway | Auth and file storage only |
| Access rules | Row-level security policies | Per-service config | In the schema (owner / authenticated) |
Firebase and Supabase are the right call when you want their depth and don't mind that an agent needs hand-holding to drive them. InsForge and Butterbase fit when a generated app needs vector search or serverless functions alongside the database. MoonDB fits when the job is a database with auth and a REST API, and the thing you care about is that an agent can stand it up in one pass and a person can read the whole schema in one screen.
Where MoonDB stops
Be clear-eyed about the trade. MoonDB runs on SQLite through Cloudflare D1, which buys fast reads at the edge and a model with almost nothing to configure. It also sets the ceiling: one writer per database and a 10 GB cap. That holds a to-do app, a CRM for a small team, or a content site with room to spare, but a write-heavy system with thousands of concurrent writers wants a dedicated Postgres. If you're weighing the two, here's how MoonDB compares to Supabase.
It's also not a vector database. If your app is doing retrieval-augmented generation and needs embeddings stored next to your data, that's a real reason to look at InsForge's vector support or a dedicated vector DB instead. MoonDB stores structured application data, the rows your generated app reads and writes, and leaves RAG to tools built for it.
For the range most agent-built apps start in, a schema an agent can write and a REST API it can call beats a feature list it can't reach. The schema and API reference covers every field type, and the walkthrough on generating a REST API from a JSON schema goes deeper on the format. If you're comparing agent-facing database tools specifically, the rundown of database MCP servers covers that angle.
FAQ
Is there a backend-as-a-service designed for AI coding agents?
Yes. Several launched recently: InsForge, Base44, Butterbase, and MoonDB among them. They differ from Supabase or Firebase in one concrete way: an agent can provision the whole backend from code, with no dashboard step. You hand over a schema and get a live database, auth, and a REST API back.
What makes a backend agent-native instead of a normal BaaS?
A normal BaaS assumes a person clicking through a dashboard to make tables and copy keys. An agent-native one is driven entirely by API: the agent sends a declarative schema, reads keys from the JSON response, and gets errors written as instructions it can act on. No human step sits in the middle.
Can a coding agent like Cursor or Claude Code set up a backend by itself?
Yes. If the backend exposes provisioning over HTTP or an MCP server, the agent can create a project, apply a schema, and start writing data without you touching a console. MoonDB does this in three calls; tools like Base44 and InsForge expose a CLI or MCP server aimed at Claude Code and Cursor.
Do I still need to write SQL or use a dashboard?
No. With a declarative backend you describe tables, fields, and access rules as JSON, and the service compiles that to SQL and runs the migration. The dashboard becomes optional. It's useful for watching what the agent built, but you don't need it to build anything.
Sources
- InsForge and its GitHub repo: open-source agent-native backend
- Base44 backend: backend with a CLI tuned for Claude Code and Cursor
- Butterbase: open-source BaaS with MCP
- Xano: best backends for AI-generated apps: the no-code vendor's take on the category
- MoonDB documentation: the schema format and full API reference